|
I tried out an approximated subgraph matching algorithm. I used Goldstone and Rogosky's (2002) algorithm called Absurdist. I applied it to text. I took the hausdorff index on a small set of words as a measure of their second order relationships within the text. I used my time travel story posted elsewhere. Since the two parts of the story mirrored each other, I thought it would be a good way to measure the degree to which the absurdist algorithm could map words onto one another. The results are interesting. 'Mother' and 'father' are confused for one another (not bidirectional, mother is confused for father in one direction, but not in the other). The characters max, phil, and akadia are confused for each other. Under some parameter settings, Otto matched with Max, which is neat (since the characters are mirrored). If I think of it later, maybe I'll post something more complete. As it is, a few notes. First, there's something weird about absurdist that doesn't scale. I had to modify the denominator of the value governing internal similarity (R in the model), such that it was treated almost like a probability distribution. Second, the output depends greatly on the preprocessing steps: window size (I tried a window of a word +- 3, 4, and 5), lemmatization/stemming (didn't do any of that), keeping stop words (kept it all in there), whether contexts spanned periods/line breaks (they did for me). Additionally, the parameters within the model play a large role. By changing chi and beta (the coefficients controlling inhibition and similarity, respectively), I can get varying results. For instance, here's when beta=.8 and chi = .2: 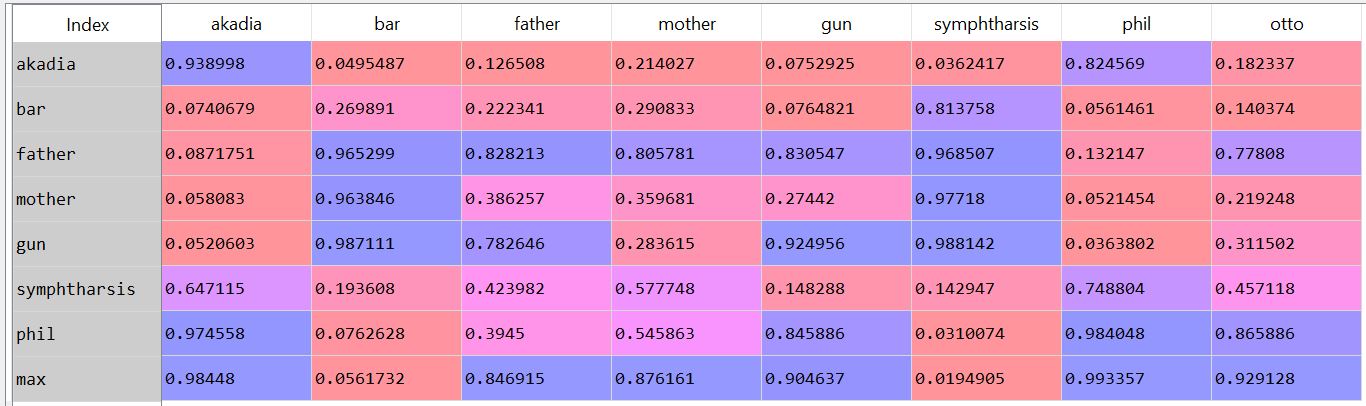 And if I change inhibition to be greater (beta = .4, chi = .6): 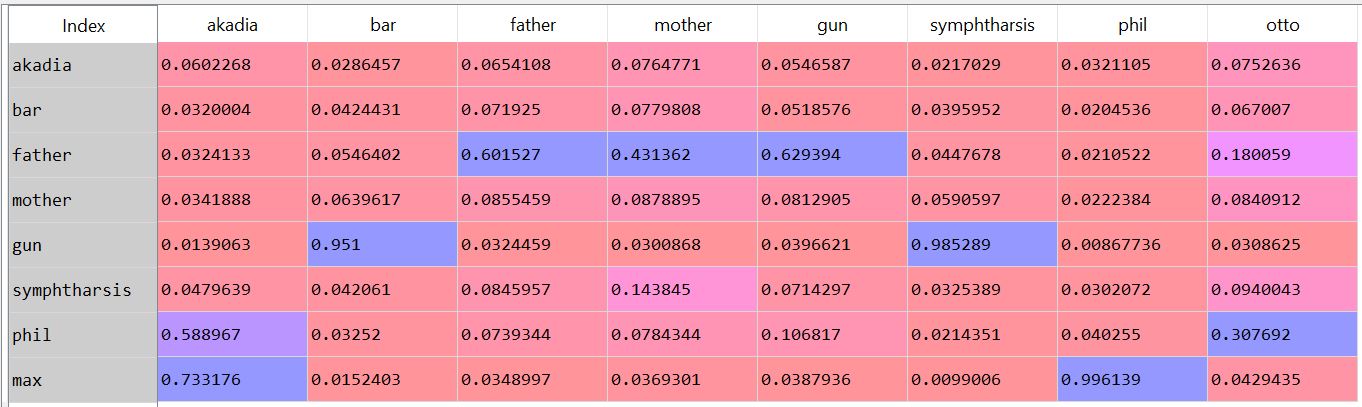 Same number of steps, but the low inhibition coefficient seems nicer (it's late, give me a break) (also, I would make nicer heatmaps rather than screenshots of the pandas dataframe, but again, it's late). The goal was to see whether absurdist would be able to adequately map the characters/words onto one another. It seems like we can (more or less) under particular conditions. Maybe I'll do some more work into making a robust pipeline. The code for this is on github. I use some functions in the code that I didn't include in the repository. Deal with it. The code for absurdist is there, so that might be useful. (I took a look at the java code that's posted online. It's in java, so it's too many hundreds of lines long. This sort of algorithm seems best implemented as matrix operations. As such, my implementation is ~50 lines long. Of course, I need to figure out why the thing isn't scaling, but I'm pretty sure the answer isn't in an extra thousand lines of code...) Cited: Goldstone, R. L., & Rogosky, B. J. (2002). Using relations within conceptual systems to translate across conceptual systems. Cognition, 84(3), 295-320.
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
AuthorIt's bad right now. It'll get better. Archives
April 2020
Categories
All
|
 RSS Feed
RSS Feed
