|
For those of you who are avid followers of this blog (I know you all by name), you'll be aware that I've explored different assumptions in RVAs regarding whether a word should predict a context as a whole or the individual words in the context. As it turns out, the answer is both (go figure. the way to be a scientist is to just answer both to everything #shortcut.) But up till now I had no empirical or theoretical work to reference. BUT I've recently read a paper on similarity and discrimination that answered a lot of questions, and provides an empirical basis for what phenomena matter in applying a learning model. I hope to post a series of recreations of the computational modeling performed by Pearce in the paper. Pearce fiddles with the Rescorla-Wagner learning model, which is used in interesting ways but I haven't yet attempted to implement. As it turns out, psychologists aren't mathematicians, and the algorithmic definition of the RW learning model in both the original paper and in Pearce's description leave a little open for interpretation. The first thing I learned in Pearce's work is that he plots the learning for multiple discriminators. 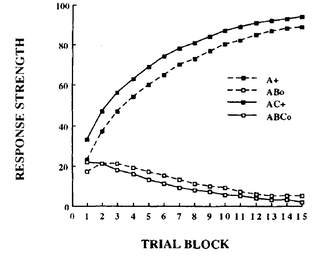 Figure 1 from Pearce (1994). Shows the learning trajectories for two discriminators (I discovered this the ... not direct way -- that is, it didn't say it explicitly in the paper). If you train a single discriminator on this set of stimulus-response pairings, you get the following plot 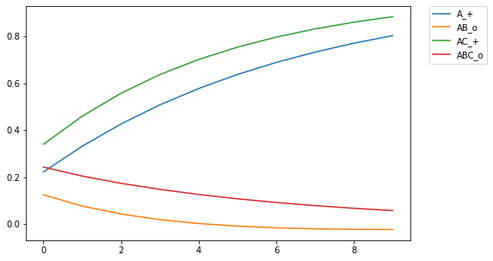 Notice a qualitative difference in ABC_o relative to AB_o. ABC_o has an overall higher response strength than AB_o, contrary to what is reported by Pearce (1994). Also, the response for AB_o goes below the asymptotic minimum of 0, which is strange and surprising. In training, this only occurs for AB_o after being trained on ABC_o, indicating something unique about the interaction between the two training instances. Of course, this difference indicates that there is something about the implementation that is underspecified in my code. It turns out that rather than training a single discriminator on all four stim-response pairings, Pearce trained a discriminator on (A_+,AB_o) and another on (AC_+, ABC_o). In my implementation, this yielded the following plot: 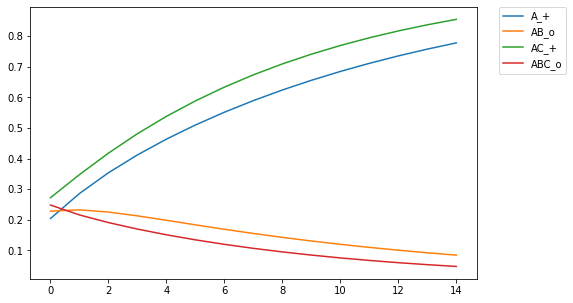 The learning trajectories in this plot replicate those reported in Pearce (1994). Woohoo!
There are many demonstrations of the limitations of the RW learning model, as well as modifications to the model so that it can replicate key empirical trends. My goal is to create a general purpose implementation of all of the modifications that Pearce explores (yes, I know there are libraries with RW implementations available, but the point of the paper is demonstrating the shortcoming of the learning rule). I also hope to replicate the algorithmic output he reports. Finally, assuming I am able to demonstrate my understanding of the rules via implementation, I have a few ideas that I'd like to explore. I'm not going to write them down here, because they're already in my notebook and that would be redundundant.
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
AuthorIt's bad right now. It'll get better. Archives
March 2021
Categories
All
|
 RSS Feed
RSS Feed
