|
I've been playing with github recently. I thought it could be useful in handling experiment manipulations. I made a master branch for an experiment, then I have branches for each of the experimental manipulations. So far it seems pretty effective. It's a web experiment, and so when I want to collect data in a particular manipulation, I do a 'git checkout manipulation' call, and all of the files are updated appropriately. It sends the data to the same database, so I have branch IDs associated with each experimental manipulation, stored in the same tables. Also, I modify the readme per branch to track what the particular manipulation is. I'm kinda proud of this as a functional implementation for managing experiment variation. I've been keeping notes on best practices in the github repo readme. Unfortunately, I can't make the repo public as I accidentally included login info in a php file (didn't follow the best practice of employing the .gitignore file correctly smh). As it is, I'll just post my notes here. Maybe at some point I'll copy the repo without the sensitive info as a demonstration. ## General Operations
Master branch serves as main feature hub. Branches serve as experimental variations. Experimental variations include: distributions Each branch must include a 1) branch ID, which is included in the branch readme, and included in index.html to be saved with user data. 2) a thorough description of the experimental condition variations in the given branch. The readme for each branch indicates parameters specific to that branch only. Central modifications to the readme exist only on master branch. ## Experiment branch parameters Branch ID: Number of Cities: Distribution: Training Repititions: Number of Blocks: Sentence recognition questions per block: Sentences per block: Statement Sampling: Other modifications: ## General notes on using github for experiment development ### version management of experiments with github - local versions on computer - hosted on remote server - need to manage multiple variations of experiment ### solution: use git branching for each version of experiment ### must: incorporate documentation for each branch indicating version have root where core functionality is maintained versions are variations of master ### cannot: merge branch to master - the point is to have each manipulation of experiment well defined as branch ### steps: - created root experiment git repo (from local, github desktop) - when creating git repo that requires server access, use .gitignore to prevent copying sensitive info (passwords) to github - identical file structures for local and server (exists outside individual repo) - updated support repos (have a js plugin repo sitting, now it's active part of system) - copied repos to server - 'git clone https...' - had to change the user so that I got the credit instead of Rob - 'git config --list' shows configuration for git repo - 'git config user.name 'my_username' - updates git username associated with repo mods - 'git config user.email '[email protected]' - updates git email address - necessary to link account - Temporarily saving github credentials in cache - 'git config credential.helper cache' - followed by pull/push command, username and password are saved in cache for default 900 seconds - 'git credential-cache exit' - manually clears cache, probably good practice prior to logout ### Useful Git commands - Create a branch - I use Github desktop to manage this steps - Switch between branches - git checkout [branch] - View all branches - git branch ### Best practices for using git to manage experimental variations - Use the '.gitignore' file - Do not upload files with usernames and passwords to github - Log any files or folders with server access information into the .gitignore file to prevent accidental data insecurity - Use the master branch for the main code. For experimental variations, create a new branch. - Each branch must work independently, and any data logged must be tagged according to the variation. - In this experiment, I used multiple tables to track data. I shouldn't have. Instead, it would probably be better to track all data from an experiment in the same SQL table. - This includes any variation for the expriment. Not every entry will fill every column, but it will lead to more concise organization in the long run.
0 Comments
A friend of mine just got a dog, and he asked me for advice. I proceeded to send him a tome. I figure I may as well put the advice here.  This is my dog. His name is Bojack. He's pretty cool I guess. (When I see people walking their dogs, I angrily think about how my dog is cuter than their dog) Here's the advice I gave my friend: Let's see, I got bojack when he was big, though still a bit puppish and not great at peeing outside. my first suggestion is to buy a shload of carpet cleaner second suggestion is to take her outside every thirty minutes. in a couple of weeks you could up it to every hour, then every two hours. That's mostly how I got bojack to be good about peeing outside. third suggestion is to kennel train. I have a pamphlet somewhere. give me a sec  I can't find it. here's a rundown and you can look up more specific information elsewhere. Feed your dog in the kennel. don't shut the door, just put the food bowl in there and let her eat. When she's done, she's done. After a week or two of that, you can start training her to go into the kennel (idk how training goes with younger pups, it might be early to start training word commands). The eventual goal is that the dog goes to the kennel immediately/enthusiastically every time you give the command. Reward it EVERY TIME (none of this variable reward bullshit, the dog is going to be stuck in there for a few hours, the least you can do is give it a treat). Also, kennel your dog up every time you leave the house for at least a year. None of this free range shit. It's only after a year that your dog has well-established habits, and you can start leaving it in a room, and then EVENTUALLY free reign of the house Older dogs behave better than younger dogs. Tired dogs behave better than fresh dogs  Think ahead about the sorts of things you want your dog to be able to do. The most important thing for me was for bojack to drop something when I told him to. The worst thing I could imagine would be my dog biting some kid and not letting go. Here's a youtube channel I watched for how-tos on this and other topics: https://www.youtube.com/channel/UCZzFRKsgVMhGTxffpzgTJlQ Dogs are highly social and will pay attention to you for cues on their behavior. That is to say, your actions strongly impact the behavior and general temperament of the dog. You are a skinner box. If the dog does something you don't want it to do, don't reinforce it. If it does something you want it to do, positively reinforce it IMMEDIATELY (within a couple seconds, if you wait longer, the association between reward and the behavior you're trying to reinforce gets weak). Likewise, if it does something bad and you punish it, punish immediately, and then give a command that the dog can obey that you can reward (I have bojack sit, stay, come). Rewarding positive behavior should happen six times as frequently as punishing negative behavior.  Never hit your dog.  I haven't really focused on teaching bojack tricks. If I'm training something new, it's usually functional. That's just my preference. (caveat, when I'm feeding him, I ask him where I should put the food, and he points at the bowl. That's kindof fun)
The things I think are important to teach my dog are, broadly, things to keep him alive (sit, stay, wait - since I don't have him on a leash nowadays, full disclosure, I had him for a year and a half before I even thought about doing that), and things to keep me from hating him (jumping at me, eating food that I didn't give him, sitting and waiting while I fill his bowl, etc). As you go through your new daily routine, think about how the dog is behaving and how your actions elicit different behaviors. Then choose the actions that elicit the behaviors from the dog that make you like the dog better. I tried out an approximated subgraph matching algorithm. I used Goldstone and Rogosky's (2002) algorithm called Absurdist. I applied it to text. I took the hausdorff index on a small set of words as a measure of their second order relationships within the text. I used my time travel story posted elsewhere. Since the two parts of the story mirrored each other, I thought it would be a good way to measure the degree to which the absurdist algorithm could map words onto one another. The results are interesting. 'Mother' and 'father' are confused for one another (not bidirectional, mother is confused for father in one direction, but not in the other). The characters max, phil, and akadia are confused for each other. Under some parameter settings, Otto matched with Max, which is neat (since the characters are mirrored). If I think of it later, maybe I'll post something more complete. As it is, a few notes. First, there's something weird about absurdist that doesn't scale. I had to modify the denominator of the value governing internal similarity (R in the model), such that it was treated almost like a probability distribution. Second, the output depends greatly on the preprocessing steps: window size (I tried a window of a word +- 3, 4, and 5), lemmatization/stemming (didn't do any of that), keeping stop words (kept it all in there), whether contexts spanned periods/line breaks (they did for me). Additionally, the parameters within the model play a large role. By changing chi and beta (the coefficients controlling inhibition and similarity, respectively), I can get varying results. For instance, here's when beta=.8 and chi = .2: 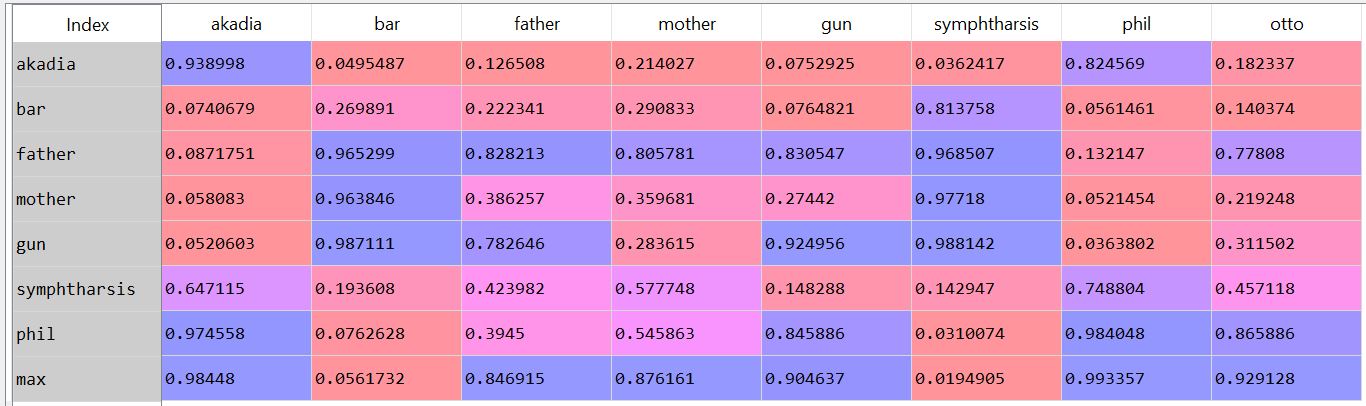 And if I change inhibition to be greater (beta = .4, chi = .6): 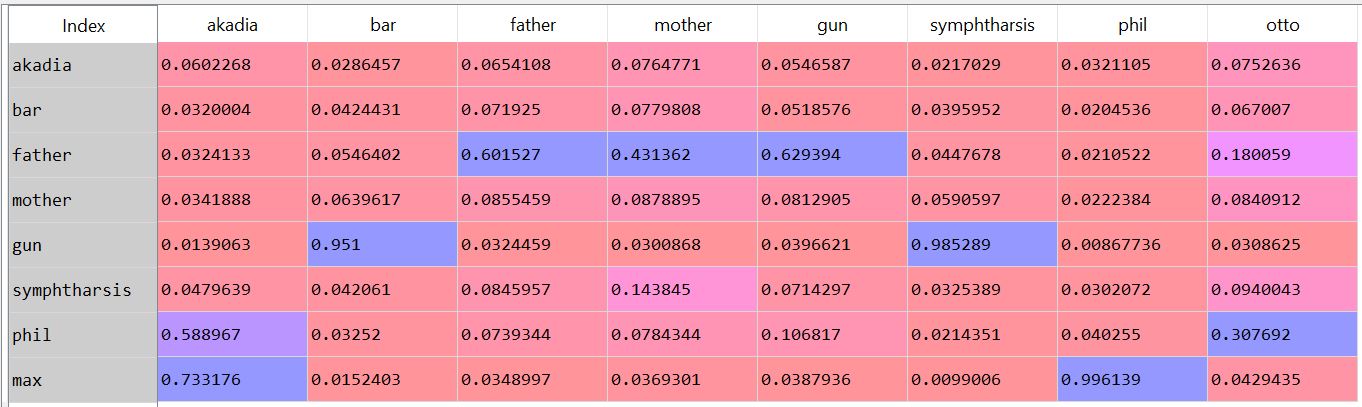 Same number of steps, but the low inhibition coefficient seems nicer (it's late, give me a break) (also, I would make nicer heatmaps rather than screenshots of the pandas dataframe, but again, it's late). The goal was to see whether absurdist would be able to adequately map the characters/words onto one another. It seems like we can (more or less) under particular conditions. Maybe I'll do some more work into making a robust pipeline. The code for this is on github. I use some functions in the code that I didn't include in the repository. Deal with it. The code for absurdist is there, so that might be useful. (I took a look at the java code that's posted online. It's in java, so it's too many hundreds of lines long. This sort of algorithm seems best implemented as matrix operations. As such, my implementation is ~50 lines long. Of course, I need to figure out why the thing isn't scaling, but I'm pretty sure the answer isn't in an extra thousand lines of code...) Cited: Goldstone, R. L., & Rogosky, B. J. (2002). Using relations within conceptual systems to translate across conceptual systems. Cognition, 84(3), 295-320. Most words have multiple senses.
I was looking at the occurrence of 'bee' in the TASA corpus. Of course, there's the insect, but then a couple of sentences popped up discussing spelling bees. Of course, this isn't a ground breaking observation. However, I could use the measure of second order relatedness I'm developing on the contexts that represent a single word. I could cluster the contexts together. Some (arbitrary?) threshold of cluster cohesiveness vs intercluster distance as definition for a given word sense. When comparing meanings between words, compare on the basis of the cluster of word senses that match, rather than also including the usages that don't relate to the word sense under scrutiny. So a dear friend and long time reader of this blog pointed out that there was an error in my time travel story - I had accidentally included a page twice (NOT a literary device). So here's the updated version: I should make it clear that there are time travel stories that are good. To be clear, these are exceptions to the rule.
Exceptions include: Back to the Future About Time Groundhog Day Terrible time travel stories: Looper ... I'm not actually going to add to this list. They're all just bad. This is a brainstorm.
Using measures of first and second order information, it is possible to get valuable distributional information regarding the meanings of words from a small corpus. Potentially apply these measures to books, poems, or ask human subjects to talk about a given topic for a while. Measure first and second order statistics on small corpus. Yields two nxn matrices, where n=number of words. Maybe preprocessing, maybe not. If we want to use the phrase 'semantic network', this is what I am referring to from now on. Compare matrices from one corpus to matrices from another corpus using subgraph isomorphism techniques. Overlap may be in the form of a given click - how well matched are two clicks. Overlap may be in the number of clicks. Overlap may be in the amount of the network subsumed in clicks. Use set theoretic measures for guidance and various applications. Potential outcomes. May be able to identify metaphors in literature and poetry. May be able to identify where students lack understanding on a given topic. May be able to predict the degree to which two human subjects agree or are able to communicate on given topics. Time travel stories are always bad. They're just bad. I could rant, but if you agree with me there's no need, and if you disagree there's no point. Anyway, I wrote a time travel story. If you are a person who is reading this blog post, I have extremely low expectation that you will figure out how to read this story. If you're not a person reading this blog post, I have zero expectation that you will figure out how to read this story. The only hint I'll put here is that you have to start by printing it out. I've been going back and forth about the degree to which an artistic endeavor should be adapted to the expectations of a potential viewer. I suppose expectations must be aligned in order for communication to occur (I think that; it may not actually be the case). But at some point, I have something that I want to communicate that doesn't fit into the regular syntax. The idea exceeds the form in which it ought be placed. The gift doesn't fit the wrapping paper. This story isn't that big of an idea. It's just odd enough shaped that I don't expect people to put in the effort to understand it. Unless I shove it in their face and bother them until they finish it. This is a burp of an idea. The roughness of the post reflects the lack of manners of the belch.
So there's this paper that I think is really important. It's new, but it consolidates some old points in a beautiful demonstration: https://arxiv.org/abs/1906.09012 Roads&Love demonstrate that the statistical distributions of concepts as they're elicited from text (amodal sources) are well-matched by the statistical distributions of concepts as they're elicited from perceptual sources (their demonstration used visual stimuli). Okay lame and boring, what does it mean. I think this paper has huge and broad implications regarding communication and meaningful interaction. Insofar as communication requires the conceptual alignment of multiple agents, this paper implies that communication is actually possible between two agents. Okay, why is it valuable to demonstrate that communication (here, I mean the conceptual alignment of multiple agents) is actually possible. Isn't it obvious that communication is possible (here, I would cite and recite Quine and Putnam). The answer from philosophers would be no, it isn't self evident that multiple agents can align their conceptual systems such that communication is possible. Hence the value of an empirical demonstration. But more importantly, this study illuminates the constraints by which such an alignment could occur. Namely, two amodal conceptual systems could align insofar as they're based on the same underlying system of concepts. The fact that Roads&Love could align an amodal text-based system of concepts and a perceptual image-based system of concepts is due to the fact that the text upon which the amodal system of concepts is based emerges from language use that emerges from perception. The development of text is inherently grounded in perception, and therefore the two systems can be aligned. Extending this to communication, the extent two which two agents' conceptual systems are grounded in the same subset of reality (assuming that reality is the thing that is sampled for the construction of conceptual systems) determines the extent to which these systems can align, and thereby the extent to which communication can occur. What are the constraints of communication? A shared set of perceptual experiences - in order for communication to happen between agents, a conceptual system grounded in the same set of perceptual experiences is necessary. Between agents of the same kind (e.g. humans), the majority of the work is carried by the perceptual systems being nearly identical - identical perceptual systems means that the agents have access to the same subset of reality as one another. Perceptual systems that are too highly varied may yield perceptually based concept systems that are not easily aligned. But even with shared perceptual systems, the experiences accrued by an agent may be such that the yielded conceptual systems of that agent may not be well-aligned to another agent. La vie. But moreover, since the most interesting this is the conceptual alignment between agents that can communicate, we need to talk about the conceptual systems that emerge from amodal sources, such as language or text. (Language serves as a means of sharing conceptual systems) If the amodal conceptual systems between two agents are not well-aligned, it might be for two (or more?) reasons. First, it might be because the perceptual experiences accrued by the agents from which the linguistic conveyance of amodal conceptual systems are derived are thoroughly dissimilar (can communication happen in this case? it's hard to say); in this case, even though linguistic inputs are well-aligned to perceptual experiences, conceptual alignment becomes challenging. Second, it might be that, even though the perceptual experiences of the agents are aligned, the construction of the linguistic inputs for one or both of the agents emerge from a different statistical distribution than that which is accessible from perception (honestly, I think this is an interesting case, and potentially a source of ought). So then, how do we increase the degree to which communication can occur between agents? If shared perceptual experiences generate conceptual systems that can be aligned, then as shared experiences between agents increases, the degree of possible communication between agents increases (likewise, as shared perceptual experiences decrease, the ability for agents to communicate decreases). But this is dependent on the degree to which the amodal conceptual systems align, since communication occurs through amodal avenues. If amodal conceptual systems emerge along a statistical structure that do not align with the statistical structure of that which can be perceived, then the potential of communication occurring decreases, since the conceptual systems cannot be aligned. This is really a pedantic way of saying that communication requires shared experiences, mediated by overlapping ideologies. But it provides a framework where these constructs can be formalized and empirically tested This makes a large claim about the degree to which communication can occur based on conceptual alignment. Can empirically test this. Find conceptual alignment of participants using like a similarity rating task for items in a particular domain (politics and religion are salient, could also do scientific topics, or other domains of expertise). Similarity rating task yields the conceptual system for a particular participant. Pair off participants and have them discuss topics within a particular domain for some alotment of time (10 minutes?). After discussion, have participants do an exit survey. Ask questions about how well they understood the other person's perspective, how well they conveyed their ideas, how well the other person understood what they said, whether they had to dumb down or hold back while discussing their position (did they hold back because they thought the other person wouldn't get it?) This is going to be a short blog post. I made some new jsPsych plugins for use in an experiment I'm working on. The jsPsych package facilitates psychological research by providing a convenient framework for building web applications and collecting user behavior for the applications. I have no experience using javascript prior to building this experiment, and any success with my experiment will be due to the usability of jsPsych. I highly recommend it.
I've made a few plugins that I've found useful for the experiment that I'm developing. The plugins are posted to my github. To be absolutely clear, I did not build these plugins from scratch, but rather modified the plugins included in the jsPsych package to fit my particular needs. |
AuthorIt's bad right now. It'll get better. Archives
March 2021
Categories
All
|
 RSS Feed
RSS Feed
