|
My numerous readers have been waiting with bated breath, but they must suffer this long wait no longer. For behold, I have generalized the rescorla-wagner learning model (Rescorla & Wagner, 1972) into a format that is generally interpretable in linear algebra. It turns out that psychologists are kinda bad at math, and there was some translation issues that I needed to work through to make sure everything worked the way it was supposed to. Originally, the RW update rule was as followed (equations copied from wikipedia): 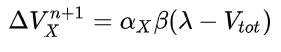 and 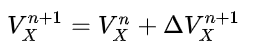 Where V_x is the association strength between a cue and a response. Alpha and beta are learning parameters (beta is a global parameter while alpha is a cue parameter). V_tot is the current activation of the response given the cue. Lambda is the expected response given a cue. As it currently stands, this notation is only good for associating a single response with a limited set of cues. The point is it's not very effective notation, so I'm going to generalize the notation to be interpretable, using modern day conventions in discussing networks. Changes in notation: Lambda -> r, where r is a row vector of real numbers, size m. c is the expected output of the model c, where c is a row vector of real numbers, size n. c is the input field of the model. V -> W, where W is a weight matrix with nxm dimensions, where n is the number of input nodes, and m is the number of response nodes alpha and beta are scalar learning parameters, and can be left as such V_tot -> never explicitly defined *anywhere*. = c @ V, where @ indicates the dot product. Using this definition, the weight matrix update rule for any cue/response, input/output pairing would be: 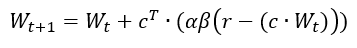 I tested this using the examples in my previous blog post. First, when training a single discriminator on all c-r pairings:
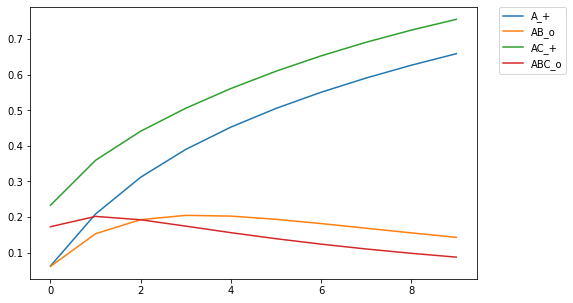
Then using 2 discriminators:
I then projected the cue field into a space with 50 dimensions. By sampling from a gaussian distribution, I generated orthogonal vectors for each of the input cues (Plate, 2003). I then got a simple linear projection of the cue field into a high dimensional space by taking the dot product between the cue field and the projection matrix. Since 50 dimensions is low, the results tend to be noisy, but get the same qualitative effect:
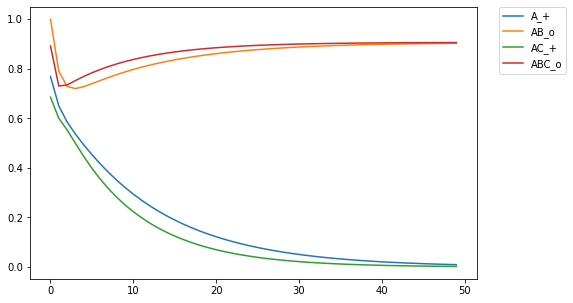
I then projected the response field into 50 dimensions, returning the cue field to the original localist representation (if you want to make sure something works, you gotta do it in baby steps. Baby steps to the door. Baby steps down the stairs. Baby steps to a generalized implementation of the rescorla-wagner learning rule). After training the network, I found the euclidean distance from the the network output to the projection matrix. When the network produced the correct output, there was a smaller distance from the response field to the projection matrix, which yields an inverted graph (note, the colors are consistent between all plots):
Finally, I tried the learning rule with projecting both the cue and response fields into a higher dimensionality. (I should find a lesson on how to work with arrays with high number of axes. I know that at this point everyone's mother plays with tensors like a toddler (me) plays with playdough. But I need a hand ugghhh). Anyway, it works and looks lovely!
Future directions. I need to do the other examples that Pearce (1994) describes. I think his configural cue theory can easily be handled in a high dimensional space using convolution (where a configuration of a and b is the convolution of two vectors representing a and b, since convolution yields an orthogonal vector). This would allow there to be an arbitrary number of configurations without the need for increasing the number of nodes in the model (i.e. no need for a third node representing the configuration of a and b). Also, out of idle curiosity, I wonder if I can train a multi-layer network using this update rule. how would that work? how would I update each layer of the network? Is it possible? With R-W there's still an objective function. But I'm thinking of something like a kohonen map, is there a way for the firings of input nodes to self organize so that they 'sort out' different types of inputs? Could be easy with orthogonal inputs - I would just want some number of output nodes to align with a given input. idk. it's just a thought. The goal is something that is a locally-derived update function, rather than a globally derived objective function. That just seems more interesting to me than like a backpropogation algorithm (if networks) or a linear algebra solution like LSA or GloVe. The code for this post is here. I don't think my previous blog post had its associated code, which I'll place here. Anyway, I've satisfactorily avoided my work so far today. I'd actually better get to it. Best, with love, yours truly, etc. References:
Pearce, J. M. (1994). Similarity and discrimination: A selective review and a connectionist model. Psychological Review, 101(4), 587. Plate, T. A. (2003). Holographic Reduced Representation: Distributed Representation for Cognitive Structures. CSLI Publications. https://books.google.com/books?id=cKaFQgAACAAJ Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. Current Research and Theory, 64–99.
0 Comments
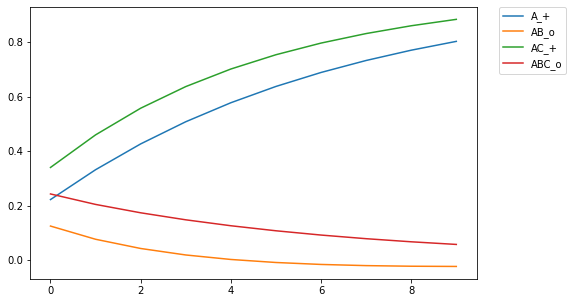
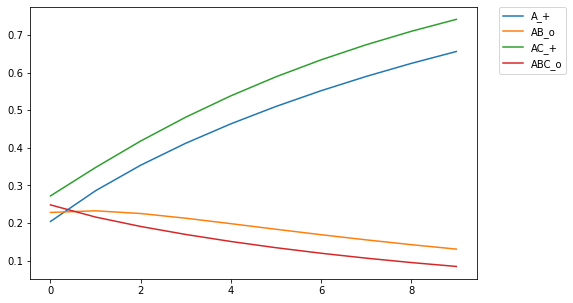
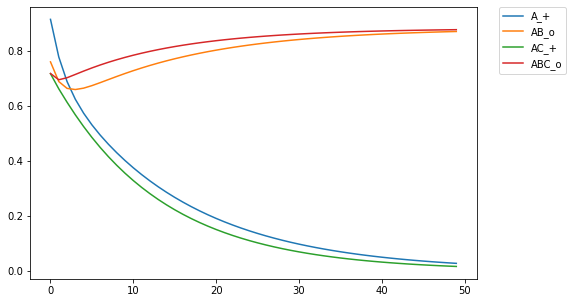
For those of you who are avid followers of this blog (I know you all by name), you'll be aware that I've explored different assumptions in RVAs regarding whether a word should predict a context as a whole or the individual words in the context. As it turns out, the answer is both (go figure. the way to be a scientist is to just answer both to everything #shortcut.) But up till now I had no empirical or theoretical work to reference. BUT I've recently read a paper on similarity and discrimination that answered a lot of questions, and provides an empirical basis for what phenomena matter in applying a learning model. I hope to post a series of recreations of the computational modeling performed by Pearce in the paper. Pearce fiddles with the Rescorla-Wagner learning model, which is used in interesting ways but I haven't yet attempted to implement. As it turns out, psychologists aren't mathematicians, and the algorithmic definition of the RW learning model in both the original paper and in Pearce's description leave a little open for interpretation. The first thing I learned in Pearce's work is that he plots the learning for multiple discriminators. 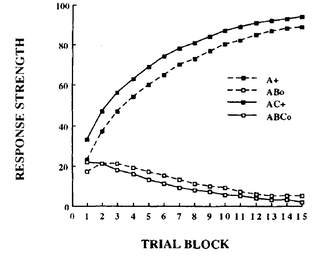 Figure 1 from Pearce (1994). Shows the learning trajectories for two discriminators (I discovered this the ... not direct way -- that is, it didn't say it explicitly in the paper). If you train a single discriminator on this set of stimulus-response pairings, you get the following plot 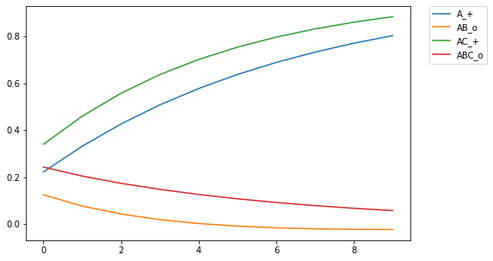 Notice a qualitative difference in ABC_o relative to AB_o. ABC_o has an overall higher response strength than AB_o, contrary to what is reported by Pearce (1994). Also, the response for AB_o goes below the asymptotic minimum of 0, which is strange and surprising. In training, this only occurs for AB_o after being trained on ABC_o, indicating something unique about the interaction between the two training instances. Of course, this difference indicates that there is something about the implementation that is underspecified in my code. It turns out that rather than training a single discriminator on all four stim-response pairings, Pearce trained a discriminator on (A_+,AB_o) and another on (AC_+, ABC_o). In my implementation, this yielded the following plot: 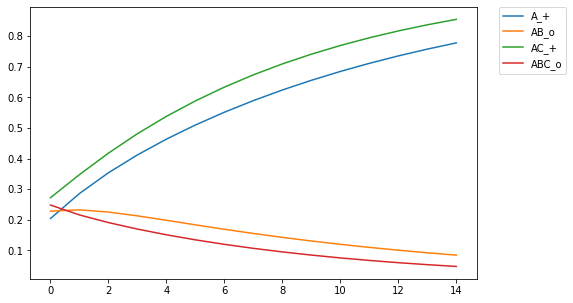 The learning trajectories in this plot replicate those reported in Pearce (1994). Woohoo!
There are many demonstrations of the limitations of the RW learning model, as well as modifications to the model so that it can replicate key empirical trends. My goal is to create a general purpose implementation of all of the modifications that Pearce explores (yes, I know there are libraries with RW implementations available, but the point of the paper is demonstrating the shortcoming of the learning rule). I also hope to replicate the algorithmic output he reports. Finally, assuming I am able to demonstrate my understanding of the rules via implementation, I have a few ideas that I'd like to explore. I'm not going to write them down here, because they're already in my notebook and that would be redundundant. My main new year's aspiration this year was to try to make complete meals. I can cook, but it's easy to just make a main dish and eat that as leftovers for the next few days. I figured it would be kinder to my taste buds to introduce variety, and to treat myself like someone I would want to serve nice food to.
And so far I've been doing a pretty good job with it. Between my roommate cooking and me eating my leftovers (I cannot stress enough how much I adore leftovers <3), I only need to plan out three meals in order to feed myself adequately for a week. As a result, I've been trying out new recipes in different cookbooks. Hands down the best cookbook I own is from America's Test Kitchen. That shit's legit. I highly recommend any cookbook from them, and do exactly what they say. You won't be disappointed. But I've tried other cookbooks as well. One such cookbook, Amy Vanderbilt's Complete Cookbook, left me sorely disappointed. So disappointed that, after having finished a truly awful meal from that cookbook, I hacked out an 800 word review of the cookbook and posted it everywhere I could find. You can find the review posted at the following links. Amazon1 Amazon2 Amazon3 Thriftbooks I like baking. Mostly because I like eating cake. I've discovered that, instead of eating it all myself, I can just offload it to my neighbors - they don't bake as much as I do, so instead of me consuming all those calories, I can spread the calories around a one-block radius. Much more eco-friendly.
An added plus is that they're less likely to get mad when you play loud music if they're slumped on the couch due to a sugar-induced coma. A common theme my advisor brings up is the idea that cosine similarity is not what humans do. I want to break that down a bit and consider what that means with regard to the representation of modalities in semantic vectors. The typical way to make use of text-derived semantic vectors is to evaluate the similarity between words (aka the cosine similarity) and compare the similarities produced by the model against similarities produced by human judgments. With this approach, the extent of the usefulness of semantic vectors is something like a k-nearest-neighbors application. Of course, knn is useful for categorization. However, knn can't be the entirety of the usefulness of semantic vectors (an ideological stance that I will pursue until I find evidence ... like a good scientist). Instead of the extent of the usefulness of semantic vectors being in knn, we can treat the distribution of points in high dimensional space as meaningful and useful as is. And just as with (nonmetric) multidimensional scaling, which is rotation and scale invariant (among other things), the exact location of a word in high dimensional semantic space isn't inherently meaningful. It's the position of a word relative to another word. Likewise, MDS is often applied such that the dimensions become interpretable in some way. In a high dimensional semantic space, the dimensions likewise aren't inherently meaningful, but it seems likely that I ought to be able to rotate the semantic space in order to yield meaningful dimensions. 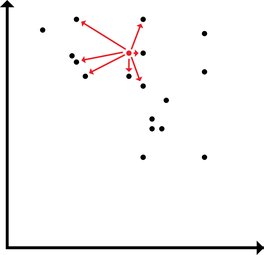 Typically, the usefulness of a vector in semantic space is applied by comparing discrete positions of a given word to the positions of other surrounding words (or of words that we would expect a model to produce a given similarity rating for). 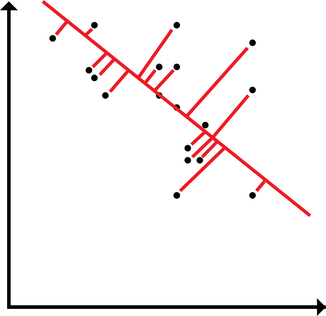 However, words may be distributed in space along some arbitrary high dimension latent within the structure that maximizes the relationship between a word in high dimensional space and some external behavior. Here, I demonstrate how words could load onto a latent dimension, where the latent dimension could predict, say, modality ratings yielded by participants. The way a word may load onto a particular modality may be latent and unobservable directly in the nearness between words in the semantic space, but may be retrievable. A simple way to implement this would be linear regression. Using sensorimotor norms as a target to predict, we could draw a line through the high dimensional space and see how each word loads onto the line. Alternatively, we could render interpretable dimensions by constructing a rotation and shift matrix. By rotating and shifting the matrix, a given dimension could be used to predict something like sensorimotor norms. Additionally, the space could be rotated to maximize each of the modalities in the norms (and then, following from the GCM, decisions could be made by applying different attentional weights to a different dimensions depending on the task. I tend to like the second approach better, but regression is easier to implement off the top of my head. Stay tuned to see whether I actually try this out! :D Note to self: I could do something like multi-fold testing in data mining using a rotation matrix yielded by procrustes analysis. I could build the rotation matrix using some subset of the data, then test the rotation matrix using the other partition. I rather prefer this to linear regression (I suppose, it's a multi-constraint linear regression): it preserves the space, and it can be interpreted in terms of a neural network.
This is a continuation of an earlier analysis. In summary, I used an artificial grammar to demonstrate that the cosine similarities predicted by a variety of DSMs could be well-characterized as linear combinations of direct measures of first and second order information. I just had the idea that I could potentially use the linear model trained on the artificial grammar to predict similarities in natural language corpora. Using the same artificial grammar, I measured the first and second order information in the corpus (specifically, I used the jaccard index to measure the first order information, and a modification of the jaccard index to measure second order information; I should probably post about those measures sometime). I then trained a cbow model on the artificial corpus, and generated a cosine similarity matrix. I then trained a linear using scikit-learn to predict the cbow similarities using the measures of first and second order information. THEN I trained a cbow model on a natural language corpora. A small and easy one I have on hand is the tasa corpus (preprocessed, removing stop words, punctuation, but no lemmatization). I sampled a subset of 50 words randomly, and generated a cosine similarity matrix (I didn't do the entire corpus - there are 65,000 words - my computer can't handle a 65,000x65,000 matrix). I also measured the first and second order information for those same words in the TASA corpus. FINALLY I predicted the cbow similarities for the tasa corpus using the first and second order measures for the tasa corpus. AND!! It didn't work. The r^2 for the predicted data was well into the negatives. as it turns out, a linear model trained on a small amount of data doesn't extend well to naturalistic data. Who knew? 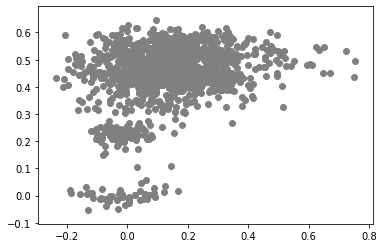 This boring looking plot is a scatter plot of the expected values against the predicted values. Along the x-axis are the cbow cosine similarities (expected), and the y-axis are the linear model predictions. While the plot looks promising, we don't get a significant prediction of the data. Wouldn't it be nice if we lived in a world where my simple prediction had been accurate? As it is, the regression produced by predicting cbow similarities in the artificial grammar do not generalize to predict the cbow similarities in the natural language corpus. Does this nullify my earlier claim that DSMs can be well-characterized as a linear combination of first and second order information? We'll see... I performed the same analysis as in the demonstration using the artificial corpus. I generated a linear model predicting cbow cosine similarities using measures of first and second order information. Instead of performing the regressions in R or using scikit-learn, I used the statsmodels api (statsmodels gives me significance values, where I'd have to calculate them with scikit).
Linear Model - Artificial grammar: cbow_sim = constant + first_order*b_0 + second_order*b_1 b_0 = -1.4*** b_1 = 1.06*** (magnitude and direction of coefficients indicates that cbow_sims are well-characterized by second order information) r^2 = 0.78 Linear Model - Natural Language Corpus: cbow_sim = constant + first_order*b_0 + second_order*b_1 b_0 = 0.19 b_1 = 0.41*** (only coefficient for second order information is significant; not large, but still significant whereas the coefficient for first order information doesn't contribute significantly to the model) r^2 = 0.11 The amount of variance predicted by the linear models significantly drops when I try to characterize cbow similarities in terms of first and second order information. First, I should note that the models DO still support my claim regarding first and second order information. The drop in the variance predicted by the linear models may be due to multiple things. First, the measure of first and second order information might not be well suited for statements longer than three words (as three word statements are used in the artificial grammar). Second, I may not be training the cbow model adequately (or, the parameters of the cbow model aren't lined up to match the assumptions of the measures of first and second order information. ... I'm going to rerun something). Is it likely that cbow is doing something qualitatively different in the natural language corpus from the artificial grammar? probably not. While I haven't put in the effort to test whether a linear model recreates the prediction of first vs second order information for every DSM I tested in my earlier post, I'm fairly confident that the claim would hold. Earlier, I talked about the underlying assumptions of RVAs, comparing summation vs convolution in binding the context into a unique unit. The formalization for a given word vector is as follows: 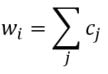 That is, the vector representing word i is the summation of all j context vectors in which i occurs. A context vector is defined as: 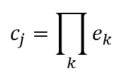 In other words, a context vector is the convolution of the environmental vectors e, where each word has a uniquely associated environmental vector. (Here I use the product symbol for convenience – there isn’t an equivalent convolution symbol; interestingly, since I’m working with random vectors, the product works as effectively as convolution, since it yields a vector orthogonal to each compositional vector). Here, my goal is to expand my definition for a random vector accumulator by casting it as matrix algebra, rather than vector algebra. Let’s assume for each word, we have a one-hot, localist representation for each word, denoted as h. Instead of a set of environmental vectors e, we have a matrix E (with shape axb, where a is the length of h, here the number of words in the corpus, and b is the output dimensionality). We can then reformulate the construction of context vectors as 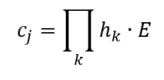 Where is the localist representation for a word. Notably, yields a vector representation. This maintains consistency between this the earlier formulation formulation of context vectors. Instead of having a single vector that represents a word wi, we implement a word matrix W composed of all word vectors representing the words (W has the same shape as E). We can then define the matrix W as 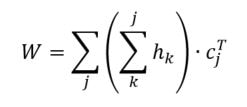 In other words, we sum all the one-hot vectors representing the words, and take the dot product with the transpose of the convolution of the words that occur in the same context, yielding a matrix representation of a given context. We then sum all such matrix representations together for all contexts in the corpus.
Since hk is a localist representation, this formulation is exactly equivalent to the earlier expression of an RVA. The usefulness of this expression is that instead of hk being a localist representation, we can instead define the vector representing a word as a distributed representation. Using a distributed representation yields a matrix W where columns no longer correspond to a given word, however this formulation yields the same predictions as a localist representation. We have, then, generalized RVAs to be effectively expressed as either localist or distributed networks. (The formalizations here might not be exactly right. I’m treating this more like a notebook than a submission for publication. At any rate, I’ve included code here where I step-by-step convert the word vector formulation to a matrix formulation.) I had this thought that cosine similarity judgments produced by distributional semantics models might be described as linear combinations of first and second order information. After all, the two main types of similarity identified in the literature are in regard to first order information (syntagmatic, thematic, related, contiguous) and second order information (paradigmatic, taxonomic, sometimes called just ‘similarity’). For an artificial corpus, I measured the first and second order associations between words. I then trained GloVe, cbow, skipgram, LSA, and PMI using the artificial grammar. I used the upper matrix (not including the diagonal) for the first and second order measurements in a linear model to predict the similarities produced by the DSMs via regression, where a DSM similarity is predicted as a weighted linear combination of first and second order information. I used python to train the DSMs and to produce the similarity matrices, I used R to produce the linear models predicting each DSM similarity matrix. I like heatmaps, so I’m going to include ALL OF THEM:
The following table presents the coefficients for each linear model, where the coefficient is in bold if p<0.001. The variance accounted for by the model is included. (is there a better way to insert tables into weebly than taking a screenshot?) 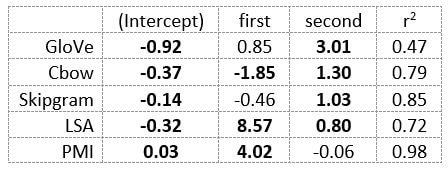 The interplay of significance and coefficient magnitudes tell an interesting story. PMI is clearly a measure of first order information. First and second order both significantly contribute to LSA, however first order information dominates. Word2Vec models are dominated by second order information (where first order information is suppressed). Glove is dominated by second order information (and it doesn’t seem like first order information is suppressed).
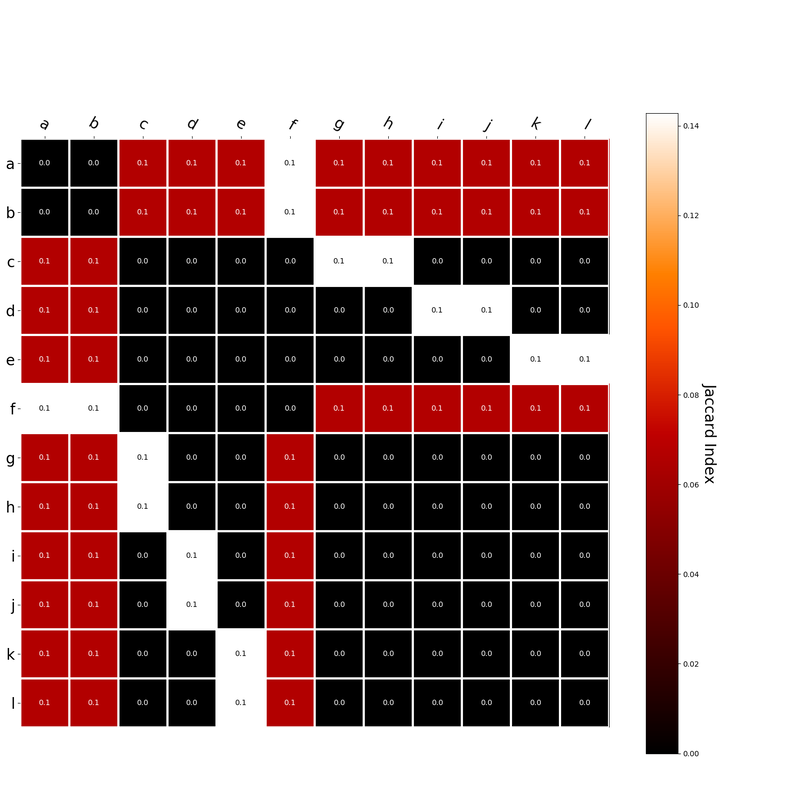
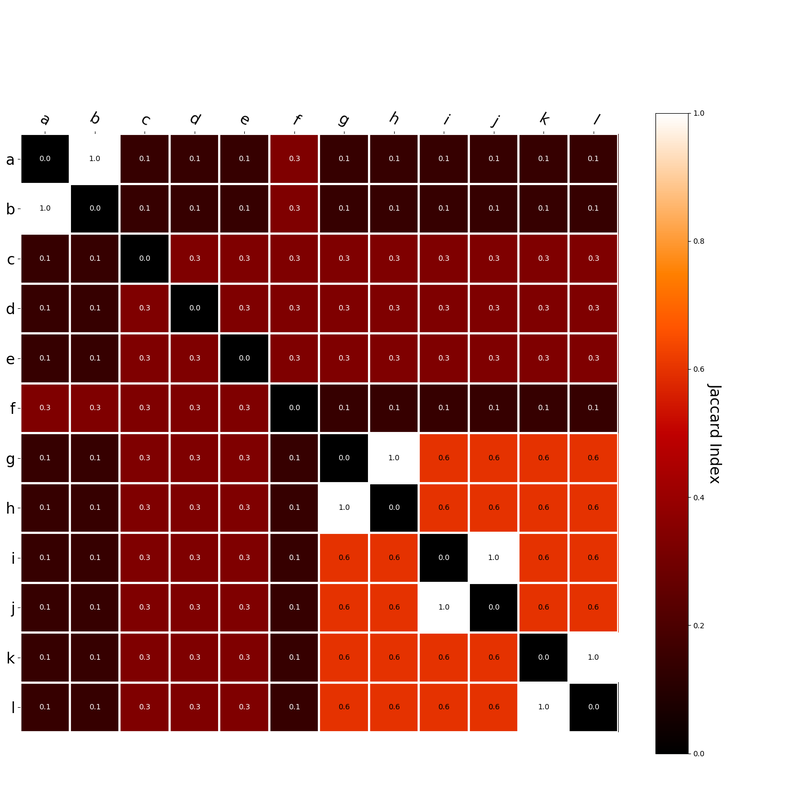
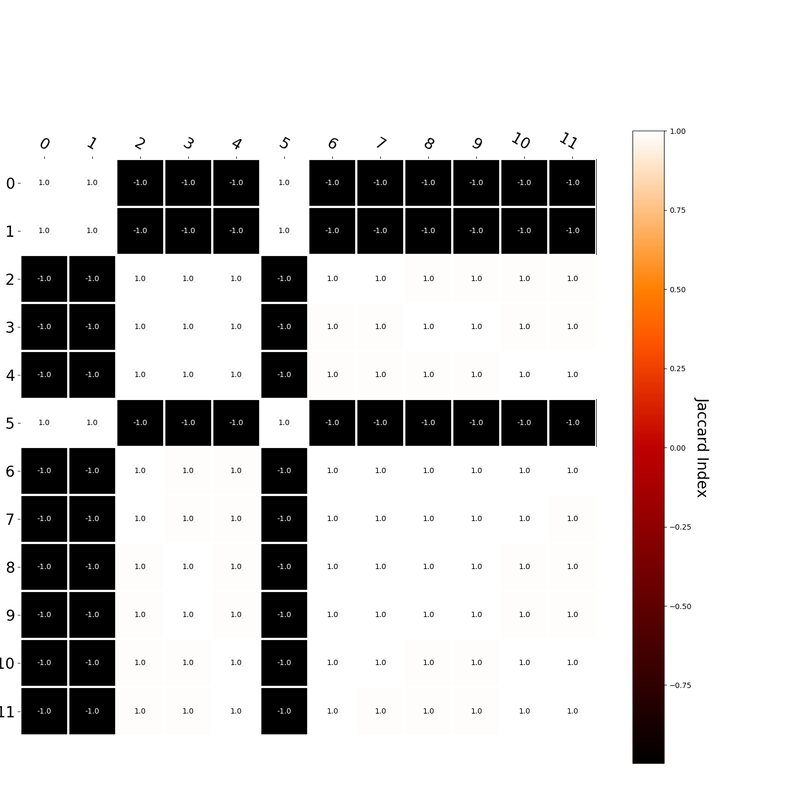
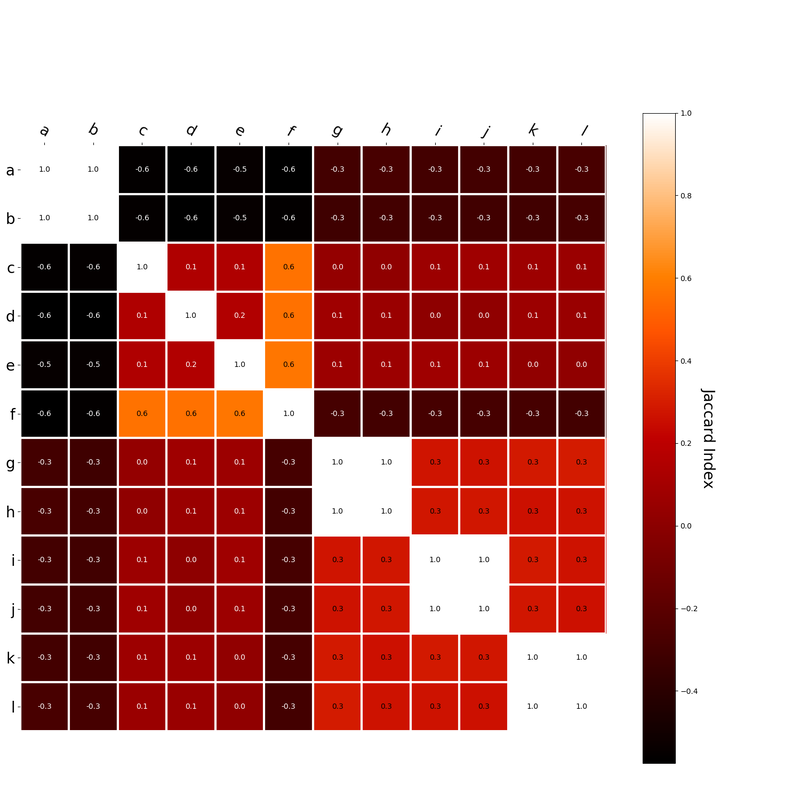
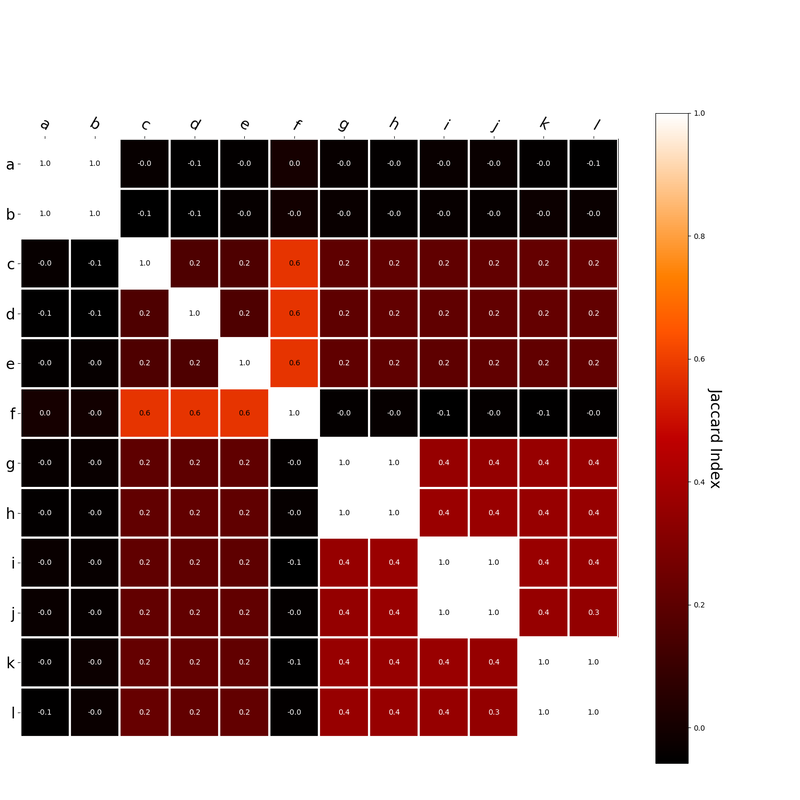
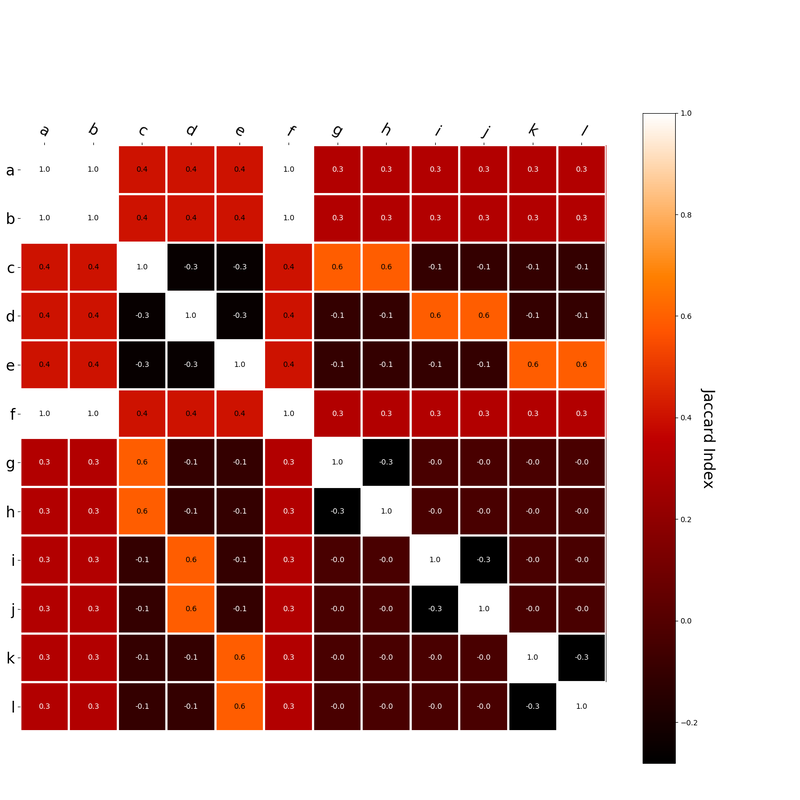
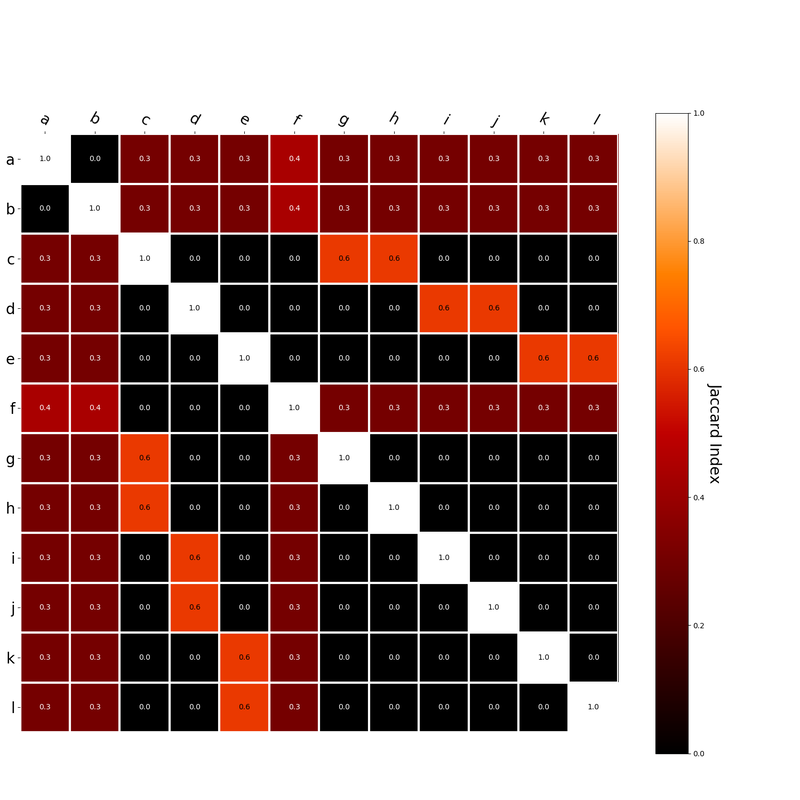
Interestingly, the variance subsumed by the linear model is the least for GloVe, at r^2=0.47. This suggests a few possibilities. It could indicate that GloVe is doing something in addition to first or second order information that is qualitatively different from what is being measured with first and second order information. It could also indicate that my method of measuring first and second order information is subject to its own limitations, where a different measure would come up with a prediction more akin to the similarity matrix produced by GloVe. When gathering similarity judgments, researchers tend to make a design decision to gather similarities based on second order information (e.g. SimLex-999), or first order information (e.g. thematic relatedness production norms from Jouravlev & McRae, 2016). Is there consistency between my measures of first/second order information and these datasets (spoiler, there is, but I only did correlations, not regression models; also, I didn’t include DSM in analysis – would DSMs match what is predicted here (eg GloVe would do well at SimLex, while PMI would do well at thematic)? Stay tuned for the next exciting adventure!) RVA can be constructed in two ways Assume the representation for a word w is a summation of the contexts in which the words occurred: 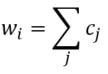 The construction of the context of a word could be the summation of the environment vectors representing the words that occurred in the context. For instance, 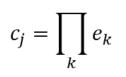 Then the representation of the word is: 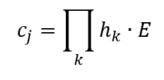 Alternatively, rather than construing the context as a summation, the vectors composing the context vector could be convolved into a vector that uniquely represents the context 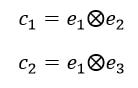 By properties of convolution, c1 and c2 are orthogonal vectors (given that the environmental vectors are orthogonal). Therefore, convolutional bindings yield a different model from the summation of environmental vectors. I used measures of first and second order statistics to yield these baseline heatmaps for word similarities: Expected first order based on jaccard index: 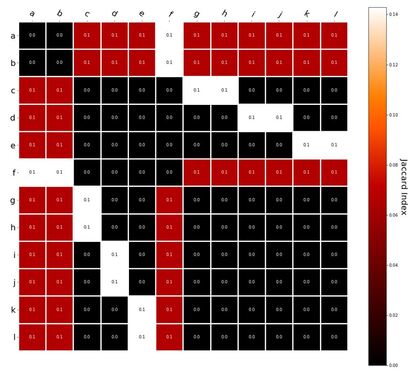 Expected second order based on jaccard index 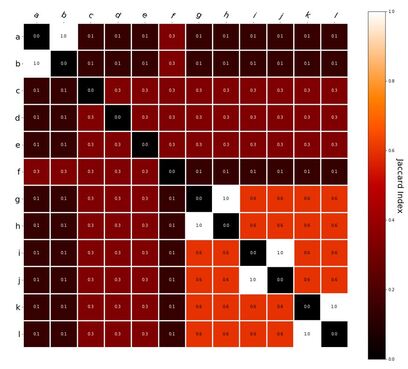 First order information using convolutional bindings: 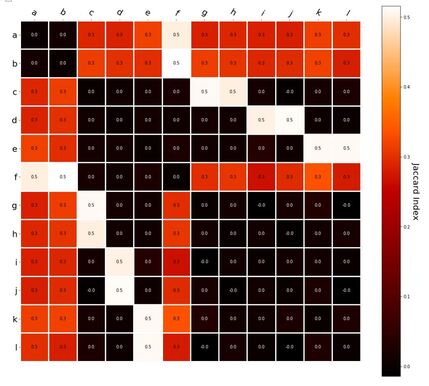 Second order information using convolutional bindings: 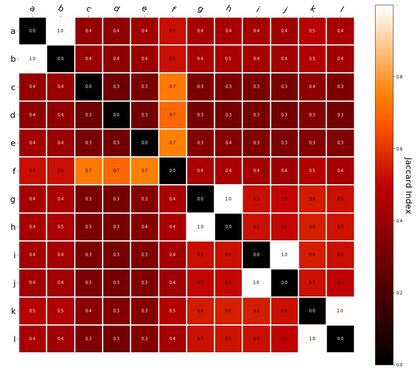 First order information using summation: 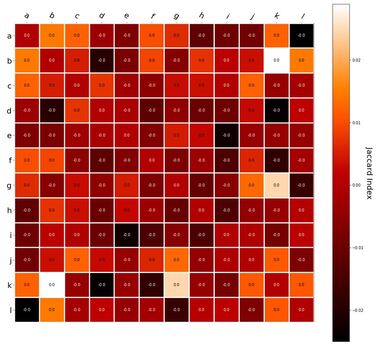 Second order information using summation: 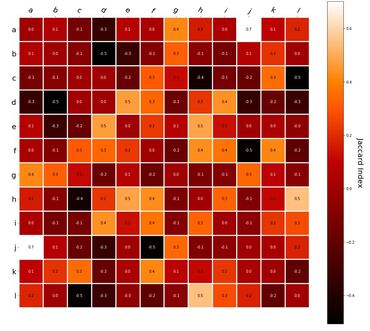 It appears that binding contexts into a unique and orthogonal vectors is necessary in order to adequately recreate first and second order information. Additionally, this highlights how effective mapping a localist representation to a random vector could be for data reduction. (Later tests could involve RVA capacity – I can’t find sources that directly address this. Maybe plate has this info). (Also, could I make an incremental learner where environmental vectors aren’t previously assigned, but weights update iteratively based on co-activation?) Code for these analyses are available at my github. I don't like the way performance of semantic models is reported. It's impossible to compare results between papers. The results are as much a function of corpus choice and pre-processing as they are of the algorithm itself.
I think in my reporting of any new or unique set of data, I should submit results from basic DSMs - GloVe, LSA, CBOW, skip-gram, BEAGLE. That would demonstrate the effect I'm presenting relative to all of the models when under the same constraints of corpus choice and pre-processing. |
AuthorIt's bad right now. It'll get better. Archives
March 2021
Categories
All
|
 RSS Feed
RSS Feed
